Publications
Check also on Google Scholar, Semantic Scholar, DBLP, and ACM DL.
2026
- arXiv’26Kill it with FIRE: On Leveraging Latent Space Directions for Runtime Backdoor Mitigation in Deep Neural NetworksEnrico Ahlers, Daniel Passon, Yannic Noller, and Lars GrunskearXiv preprint arXiv:2602.10780, 2026
Machine learning models are increasingly present in our everyday lives; as a result, they become targets of adversarial attackers seeking to manipulate the systems we interact with. A well-known vulnerability is a backdoor introduced into a neural network by poisoned training data or a malicious training process. Backdoors can be used to induce unwanted behavior by including a certain trigger in the input. Existing mitigations filter training data, modify the model, or perform expensive input modifications on samples. If a vulnerable model has already been deployed, however, those strategies are either ineffective or inefficient. To address this gap, we propose our inference-time backdoor mitigation approach called FIRE (Feature-space Inference-time REpair). We hypothesize that a trigger induces structured and repeatable changes in the model’s internal representation. We view the trigger as directions in the latent spaces between layers that can be applied in reverse to correct the inference mechanism. Therefore, we turn the backdoored model against itself by manipulating its latent representations and moving a poisoned sample’s features along the backdoor directions to neutralize the trigger. Our evaluation shows that FIRE has low computational overhead and outperforms current runtime mitigations on image benchmarks across various attacks, datasets, and network architectures.
@article{ahlers2026killfireleveraginglatent, title = {Kill it with FIRE: On Leveraging Latent Space Directions for Runtime Backdoor Mitigation in Deep Neural Networks}, author = {Ahlers, Enrico and Passon, Daniel and Noller, Yannic and Grunske, Lars}, year = {2026}, eprint = {2602.10780}, archiveprefix = {arXiv}, primaryclass = {cs.SE}, url = {https://arxiv.org/abs/2602.10780}, journal = {arXiv preprint arXiv:2602.10780}, } - arXiv’26Before Autonomy Takes Control: Software Testing in RoboticsNils Chur, Thiago Santos Moura, Argentina Ortega, Sven Peldszus, Thorsten Berger, Nico Hochgeschwender, and Yannic NollerarXiv preprint arXiv:2602.02293, 2026
Robotic systems are complex and safety-critical software systems. As such, they need to be tested thoroughly. Unfortunately, robot software is intrinsically hard to test compared to traditional software, mainly since the software needs to closely interact with hardware, account for uncertainty in its operational environment, handle disturbances, and act highly autonomously. However, given the large space in which robots operate, anticipating possible failures when designing tests is challenging. This paper presents a mapping study by considering robotics testing papers and relating them to the software testing theory. We consider 247 robotics testing papers and map them to software testing, discussing the state-of-the-art software testing in robotics with an illustrated example, and discuss current challenges. Forming the basis to introduce both the robotics and software engineering communities to software testing challenges. Finally, we identify open questions and lessons learned.
@article{chur2026autonomytakescontrolsoftware, title = {Before Autonomy Takes Control: Software Testing in Robotics}, author = {Chur, Nils and de Moura, Thiago Santos and Ortega, Argentina and Peldszus, Sven and Berger, Thorsten and Hochgeschwender, Nico and Noller, Yannic}, year = {2026}, eprint = {2602.02293}, archiveprefix = {arXiv}, primaryclass = {cs.SE}, url = {https://arxiv.org/abs/2602.02293}, journal = {arXiv preprint arXiv:2602.02293}, } - Preprint’26Towards Automated Test Adaptation in Fork Ecosystems via Large Language ModelsMukelabai Mukelabai, Wesley Schurkus, Yannic Noller, and Thorsten Berger2026
Fork-based software ecosystems enable independent evolution, but fragment the quality assurance efforts. Although tests developed in one fork are often relevant to others, direct reuse is rare and can be difficult, due to API drift, refactorings, dependency evolution, or other changes. Prior work has shown that many tests are potentially reusable across forks, yet adapting them remains a largely manual task. This paper explores LLM-assisted test case adaptation as a new direction for automating test propagation in fork ecosystems. We propose a compiler-aware, iterative adaptation technique that integrates tests from one fork into another and leverages large language models (LLMs) to repair incompatibilities revealed by build failures. We report early empirical results on Java fork pairs, showing that LLM guidance can successfully adapt tests in 87.5% of cases where direct reuse fails due to modifications required to the test code itself. Finally, we outline research directions toward soundness-aware, scalable test propagation using foundation models.
@article{testAdaptionForks, title = {Towards Automated Test Adaptation in Fork Ecosystems via Large Language Models}, author = {Mukelabai, Mukelabai and Schurkus, Wesley and Noller, Yannic and Berger, Thorsten}, year = {2026}, }
2025
- ASE’25Risk Estimation in Differential Fuzzing via Extreme Value TheoryRafael Baez, Alejandro Olivas, Nathan K Diamond, Marcelo Frias, Yannic Noller, and Saeid Tizpaz-NiariIn 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2025
Differential testing is a highly effective technique for automatically detecting software bugs and vulnerabilities when the specifications are not available, or they involve an analysis over multiple executions simultaneously. Differential fuzzing, in particular, operates as a random process, observing differences in outputs or behaviors between similar inputs to generate the next inputs. However, this process lacks any guarantees on the worst-case outcome: from a differential fuzzing campaign that has observed a certain difference, what is the risk of observing larger differences if we run the fuzzer for one or more steps? This paper investigates the application of Extreme Value Theory (EVT) to address the risk of missing or underestimating differential bugs. The key observation is that differential fuzzing as a random process resembles the maximum distribution of observed differences. Hence, EVT, a branch of statistics dealing with extreme values, is an ideal framework to analyze the tail of the differential fuzzing campaign to contain the risk. We perform experiments on a set of real-world Java libraries and use a differential fuzzing that finds information leaks via side channels in these libraries. We first explore the feasibility of EVT for this task and the optimal hyperparameters for EVT distributions. We then compare EVT-based extrapolation against baseline statistical methods like Markov’s and Chebyshev’s inequalities, and the Bayes factor. EVT-based extrapolations outperform the baseline techniques in 14.3% of cases, and it ties with the baseline in 64.2% of cases. Finally, we evaluate the accuracy and performance gains of EVT-enabled differential fuzzing in real-world Java libraries, where we reported an average saving for tens of millions of byte-code executions.
@inproceedings{diffuzz_risk_ase25, author = {Baez, Rafael and Olivas, Alejandro and Diamond, Nathan K and Frias, Marcelo and Noller, Yannic and Tizpaz-Niari, Saeid}, booktitle = {2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE)}, title = {Risk Estimation in Differential Fuzzing via Extreme Value Theory}, year = {2025}, pages = {342-354}, doi = {10.1109/ASE63991.2025.00036}, } - ASE-NIER’25Simulated Interactive DebuggingYannic Noller, Erick Chandra, Srinidhi Chandrashekar, Kenny Choo, Cyrille Jegourel, Oka Kurniawan, and Christopher M. PoskittIn 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2025
Debugging software, i.e., the localization of faults and their repair, is a main activity in software engineering. Therefore, effective and efficient debugging is one of the core skills a software engineer must develop. However, the teaching of debugging techniques is usually very limited or only taught in indirect ways, e.g., during software projects. As a result, most Computer Science (CS) students learn debugging only in an ad-hoc and unstructured way. In this work, we present our approach called Simulated Interactive Debugging that interactively guides students along the debugging process. The guidance aims to empower the students to repair their solutions and have a proper "learning" experience. We envision that such guided debugging techniques can be integrated into programming courses early in the CS education curriculum. To perform an initial evaluation, we developed a prototypical implementation using traditional fault localization techniques and large language models. Students can use features like the automated setting of breakpoints or an interactive chatbot. We designed and executed a controlled experiment that included this IDE-integrated tooling with eight undergraduate CS students. Based on the responses, we conclude that the participants liked the systematic guidance by the assisted debugger. In particular, they rated the automated setting of breakpoints as the most effective, followed by the interactive debugging and chatting, and the explanations for how breakpoints were set. In our future work, we will improve our concept and implementation, add new features, and perform more intensive user studies.
@inproceedings{simulated_interactive_debugging, author = {Noller, Yannic and Chandra, Erick and Chandrashekar, Srinidhi and Choo, Kenny and Jegourel, Cyrille and Kurniawan, Oka and Poskitt, Christopher M.}, booktitle = {2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE)}, title = {Simulated Interactive Debugging}, year = {2025}, pages = {3896-3901}, keywords = {Location awareness;Systematics;Large language models;Education;Debugging;Maintenance engineering;Chatbots;Software;Programming profession;Software engineering;Intelligent Tutoring;Debugging;Software Engineering;Education}, doi = {10.1109/ASE63991.2025.00338}, } - Koli Calling’25Designing for Novice Debuggers: A Pilot Study on an AI-Assisted Debugging ToolOka Kurniawan, Erick Chandra, Christopher M. Poskitt, Yannic Noller, Kenny Tsu Wei Choo, and Cyrille JegourelIn Proceedings of the 25th Koli Calling International Conference on Computing Education Research, , 2025
Debugging is a fundamental skill that novice programmers must develop. Numerous tools have been created to assist novice programmers in this process. Recently, large language models (LLMs) have been integrated with automated program repair techniques to generate fixes for students’ buggy code. However, many of these tools foster an over-reliance on AI and do not actively engage students in the debugging process. In this work, we aim to design an intuitive debugging assistant, CodeHinter, that combines traditional debugging tools with LLM-based techniques to help novice debuggers fix semantic errors while promoting active engagement in the debugging process. We present findings from our second design iteration, which we tested with a group of undergraduate students. Our results indicate that the students found the tool highly effective in resolving semantic errors and significantly easier to use than the first version. Consistent with our previous study, error localization was the most valuable feature. Finally, we conclude that any AI-assisted debugging approach should be personalized based on user profiles to optimize their interactions with the tool.
@inproceedings{codehinter_koli25, author = {Kurniawan, Oka and Chandra, Erick and Poskitt, Christopher M. and Noller, Yannic and Choo, Kenny Tsu Wei and Jegourel, Cyrille}, title = {Designing for Novice Debuggers: A Pilot Study on an AI-Assisted Debugging Tool}, year = {2025}, isbn = {9798400715990}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3769994.3769997}, doi = {10.1145/3769994.3769997}, booktitle = {Proceedings of the 25th Koli Calling International Conference on Computing Education Research}, articleno = {41}, numpages = {7}, keywords = {Assisted debugging, programming education, intelligent tutoring systems, large language models, interactive debugging, novice programmers, AI assistants, AI tutoring, design guidelines.}, location = { }, series = {Koli Calling '25}, } - EMSE’25Shifting fuzzing left in software workflowsDylan J. Wolff, Ridwan Shariffdeen, Yannic Noller, and Abhik RoychoudhuryEmpirical Software Engineering, Jul 2025
Fuzzing has proven to be an effective tool for finding bugs in software, with Google’s OSSFuzz alone being responsible for finding thousands of critical security vulnerabilities in open source projects. As software development practices evolve, there is a growing recognition of the need to integrate security testing earlier in the development process. Yet in our survey of software practitioners, only 20% used fuzzing as part of their development workflow. In this paper, we explore how fuzzing can fit into the software development life cycle. We do so with two empirical studies, including perspectives from over 40 industry practitioners. First, in a survey of software professionals, we identify several gaps between current state-of-the-art fuzzers’ capabilities and engineers’ expectations. In particular, we find that most developers are willing to use fuzzers, but prefer shorter, more frequent fuzzing runs as part of a continuous integration/continuous deployment (CI/CD) workflow. Next, based on results of this survey, we assess state-of-the-art fuzzers’ capabilities in the context of CI/CD and local development workflows. We observe that existing fuzzers can find up to 50% of bugs within 5 minutes of fuzzing, meeting developer expectations from our survey, but that further research is needed to uncover more difficult bugs within tolerable time limits. Additionally, we see that the initial corpus and time needed to build and analyze a project for a particular fuzzer both have a significant effect on fuzzer effectiveness in this context. We hope that our work will help the community to drive wider adoption of fuzzing in the software development lifecycle.
@article{emse25_shiftleftfuzzing, author = {Wolff, Dylan J. and Shariffdeen, Ridwan and Noller, Yannic and Roychoudhury, Abhik}, title = {Shifting fuzzing left in software workflows}, journal = {Empirical Software Engineering}, year = {2025}, month = jul, day = {22}, volume = {30}, number = {5}, pages = {146}, issn = {1573-7616}, doi = {10.1007/s10664-025-10702-5}, url = {https://doi.org/10.1007/s10664-025-10702-5}, } - arXiv’25Worst-Case Symbolic Constraints Analysis and Generalisation with Large Language ModelsDaniel Koh, Yannic Noller, Corina S. Pasareanu, Adrians Skapars, and Youcheng SunarXiv preprint arXiv:2506.08171, Jul 2025
Large language models (LLMs) have been successfully applied to a variety of coding tasks, including code generation, completion, and repair. However, more complex symbolic reasoning tasks remain largely unexplored by LLMs. This paper investigates the capacity of LLMs to reason about worst-case executions in programs through symbolic constraints analysis, aiming to connect LLMs and symbolic reasoning approaches. Specifically, we define and address the problem of worst-case symbolic constraints analysis as a measure to assess the comprehension of LLMs. We evaluate the performance of existing LLMs on this novel task and further improve their capabilities through symbolic reasoning-guided fine-tuning, grounded in SMT (Satisfiability Modulo Theories) constraint solving and supported by a specially designed dataset of symbolic constraints. Experimental results show that our solver-aligned model, WARP-1.0-3B, consistently surpasses size-matched and even much larger baselines, demonstrating that a 3B LLM can recover the very constraints that pin down an algorithm’s worst-case behaviour through reinforcement learning methods. These findings suggest that LLMs are capable of engaging in deeper symbolic reasoning, supporting a closer integration between neural network-based learning and formal methods for rigorous program analysis.
@article{koh2025worstcasesymbolicconstraintsanalysis, title = {Worst-Case Symbolic Constraints Analysis and Generalisation with Large Language Models}, author = {Koh, Daniel and Noller, Yannic and Pasareanu, Corina S. and Skapars, Adrians and Sun, Youcheng}, year = {2025}, eprint = {2506.08171}, archiveprefix = {arXiv}, primaryclass = {cs.SE}, url = {https://arxiv.org/abs/2506.08171}, journal = {arXiv preprint arXiv:2506.08171}, } - arXiv’25Empirical Evaluation of Generalizable Automated Program Repair with Large Language ModelsViola Campos, Ridwan Shariffdeen, Adrian Ulges, and Yannic NollerarXiv preprint arXiv:2506.03283, Jul 2025
Automated Program Repair (APR) proposes bug fixes to aid developers in maintaining software. The state of the art in this domain focuses on using LLMs, leveraging their strong capabilities to comprehend specifications in natural language and to generate program code. Recent works have shown that LLMs can be used to generate repairs. However, despite the APR community’s research achievements and several industry deployments in the last decade, APR still lacks the capabilities to generalize broadly. In this work, we present an intensive empirical evaluation of LLMs for generating patches. We evaluate a diverse set of 13 recent models, including open ones (e.g., Llama 3.3, Qwen 2.5 Coder, and DeepSeek R1 (dist.)) and closed ones (e.g., o3-mini, GPT-4o, Claude 3.7 Sonnet, Gemini 2.0 Flash). In particular, we explore language-agnostic repairs by utilizing benchmarks for Java (e.g., Defects4J), JavaScript (e.g., BugsJS), Python (e.g., BugsInPy), and PHP (e.g., BugsPHP). Besides the generalization between different languages and levels of patch complexity, we also investigate the effects of fault localization (FL) as a preprocessing step and compare the progress for open vs closed models. Our evaluation represents a snapshot of the current repair capabilities of the latest LLMs. Key results include: (1) Different LLMs tend to perform best for different languages, which makes it hard to develop cross-platform repair techniques with single LLMs. (2) The combinations of models add value with respect to uniquely fixed bugs, so a committee of expert models should be considered. (3) Under realistic assumptions of imperfect FL, we observe significant drops in accuracy from the usual practice of using perfect FL. Our findings and insights will help both researchers and practitioners develop reliable and generalizable APR techniques and evaluate them in realistic and fair environments.
@article{campos2025empiricalevaluationgeneralizableautomated, title = {Empirical Evaluation of Generalizable Automated Program Repair with Large Language Models}, author = {Campos, Viola and Shariffdeen, Ridwan and Ulges, Adrian and Noller, Yannic}, year = {2025}, eprint = {2506.03283}, archiveprefix = {arXiv}, primaryclass = {cs.SE}, journal = {arXiv preprint arXiv:2506.03283}, url = {https://arxiv.org/abs/2506.03283}, } - CSEE&T’25Software Engineering Educational Experience in Building an Intelligent Tutoring SystemZhiyu Fan, Yannic Noller, Ashish Dandekar, and Abhik RoychoudhuryIn 37th IEEE Conference on Software Engineering Education and Training (CSEE&T 2025), co-located with ICSE 2025., Jul 2025
The growing number of students enrolling in Computer Science (CS) programmes is pushing CS educators to their limits. This poses significant challenges to computing education, particularly the teaching of introductory programming and advanced software engineering (SE) courses. First-year programming courses often face overwhelming enrollments, including interdisciplinary students who are not CS majors. The high teacher-to-student ratio makes it challenging to provide timely and high-quality feedback. Meanwhile, software engineering education comes with inherent difficulties like acquiring industry partners and the dilemma that such software projects are often under or over-specified and one-time efforts within one team or one course. To address these challenges, we designed a novel foundational SE course. This SE course envisions building a full-fledged Intelligent Tutoring System (ITS) of Programming Assignments to provide automated, real-time feedback for novice students in programming courses over multiple years. Each year, SE students contribute to specific short-running SE projects that improve the existing ITS implementation, while at the same time, we can deploy the ITS for usage by students for learning programming. This project setup builds awareness among SE students about their contribution to a “to–be–deployed" software project. In this multi-year teaching effort, we have incrementally built an ITS that is now deployed in various programming courses. This paper discusses the Intelligent Tutoring System architecture, our teaching concept in the SE course, our experience with the built ITS, and our view of future computing education.
- TOSEM’25Vulnerability Repair via Concolic Execution and Code MutationsRidwan Shariffdeen, Christopher Timperley, Yannic Noller, Claire Le Goues, and Abhik RoychoudhuryACM Transactions on Software Engineering and Methodology (TOSEM), Jul 2025
Security vulnerabilities detected via techniques like greybox fuzzing are often fixed with a significant time lag. This increases the exposure of the software to vulnerabilities. Automated fixing of vulnerabilities where a tool can generate fix suggestions is thus of value. In this work, we present such a tool, called CrashRepair, to automatically generate fix suggestions using concolic execution, specification inference, and search techniques. Our approach avoids generating fix suggestions merely at the crash location because such fixes often disable the manifestation of the error instead of fixing the error. Instead, based on sanitizer-guided concolic execution, we infer desired constraints at specific program locations and then opportunistically search for code mutations that help respect those constraints. Our technique only requires a single detected vulnerability or exploit as input; it does not require any user-provided properties. Evaluation results on a wide variety of CVEs in the VulnLoc benchmark, show CrashRepair achieves greater efficacy than state-of-the-art vulnerability repair tools like Senx. The repairs suggested come in the form of a ranked set of patches at different locations, and we show that on most occasions, the desired fix is among the top-3 fixes reported by CrashRepair.
@article{tosem25_crashrepair, title = {Vulnerability Repair via Concolic Execution and Code Mutations}, journal = {ACM Transactions on Software Engineering and Methodology (TOSEM)}, publisher = {Association for Computing Machinery}, year = {2025}, keywords = {Automated Program Repair, Vulnerability Repair, Semantic Program Analysis, Concolic Execution}, author = {Shariffdeen, Ridwan and Timperley, Christopher and Noller, Yannic and Goues, Claire Le and Roychoudhury, Abhik}, }
2024
- E&PDE’24A Transdisciplinary STEAMxD Workshop on A.I. Rescue Robotics for Pre-University StudentsJeffrey Chan Kok Hui, Melvin Lee Ming Jun, Zeng Zimou, Soon Kiat Matthew Yeo, Mei Xuan Tan, Yixiao Wang, Chee Huei Lee, Chandrima Chatterjee, Yannic Noller, Natalie Agus, Sumbul Khan, Ibrahim Thahir, Mohan R. Elara, Lay Kee Ang, and Franklin AnaribaIn 26th International Conference on Engineering and Product Design Education, Jul 2024
In this work, we apply the Singapore University of Technology and Design (SUTD)’s STEAM x D (STEAM = Science, Technology, Engineering, Arts and Mathematics, and D = Design Thinking) transdisciplinary collaborative principles to a different set of disciplines (i.e. Humanities, Artificial Intelligence, 3D printing, etc.), in a workshop which was carried out for a total of 46 participating high school students (17-18-years old) in which about 40% were female students. In this 5-day workshop the students worked in teams of 4 to 5 students along 8 SUTD instructors from different disciplines, and 10 SUTD undergraduate helpers, to solve a design challenge using a systems approach complemented with human-centric, design thinking, and engineering elements as part of our daVinci@SUTD immersion programme, which seeks to inspire youth in human-centered design and innovation that are grounded in STEM education fused with the understanding of Humanities, Arts, and Social Sciences to serve greater societal needs. In general, survey feedback showed high levels of student engagement, awareness of using Artificial Intelligence, engineering, and design thinking to address real-life problems, and overall, the students found the workshop useful and insightful.
@inproceedings{epde2024, title = {A Transdisciplinary STEAMxD Workshop on A.I. Rescue Robotics for Pre-University Students}, author = {Hui, Jeffrey Chan Kok and Jun, Melvin Lee Ming and Zimou, Zeng and Yeo, Soon Kiat Matthew and Tan, Mei Xuan and Wang, Yixiao and Lee, Chee Huei and Chatterjee, Chandrima and Noller, Yannic and Agus, Natalie and Khan, Sumbul and Thahir, Ibrahim and Elara, Mohan R. and Ang, Lay Kee and Anariba, Franklin}, booktitle = {26th International Conference on Engineering and Product Design Education}, year = {2024}, } - TOSEM’24Timing Side-Channel Mitigation via Automated Program RepairHaifeng Ruan, Yannic Noller, Saeid Tizpaz-Niari, Sudipta Chattopadhyay, and Abhik RoychoudhuryACM Transactions on Software Engineering and Methodology (TOSEM), Nov 2024
Side-channel vulnerability detection has gained prominence recently due to Spectre and Meltdown attacks. Techniques for side-channel detection range from fuzz testing to program analysis and program composition. Existing side-channel mitigation techniques repair the vulnerability at the IR/binary level or use runtime monitoring solutions. In both cases, the source code itself is not modified, can evolve while keeping the vulnerability, and the developer would get no feedback on how to develop secure applications in the first place. Thus, these solutions do not help the developer understand the side-channel risks in her code and do not provide guidance to avoid code patterns with side-channel risks. In this paper, we present Pendulum, the first approach for automatically locating and repairing side-channel vulnerabilities in the source code, specifically for timing side channels. Our approach uses a quantitative estimation of found vulnerabilities to guide the fix localization, which goes hand-in-hand with a pattern-guided repair. Our evaluation shows that Pendulum can repair a large number of side-channel vulnerabilities in real-world applications. Overall, our approach integrates vulnerability detection, quantization, localization, and repair into one unified process. This also enhances the possibility of our side-channel mitigation approach being adopted into programming environments.
@article{tosem24_pendulum, title = {Timing Side-Channel Mitigation via Automated Program Repair}, journal = {ACM Transactions on Software Engineering and Methodology (TOSEM)}, publisher = {Association for Computing Machinery}, year = {2024}, issue_date = {November 2024}, address = {New York, NY, USA}, volume = {33}, number = {8}, issn = {1049-331X}, url = {https://doi.org/10.1145/3678169}, doi = {https://dl.acm.org/doi/10.1145/3678169}, month = nov, articleno = {206}, numpages = {27}, keywords = {side-channel vulnerability, program repair, software engineering}, author = {Ruan, Haifeng and Noller, Yannic and Tizpaz-Niari, Saeid and Chattopadhyay, Sudipta and Roychoudhury, Abhik}, } - arXiv’24Codexity: Secure AI-assisted Code GenerationSung Yong Kim, Zhiyu Fan, Yannic Noller, and Abhik RoychoudhuryarXiv preprint arXiv:2405.03927, Nov 2024
Despite the impressive performance of Large Language Models (LLMs) in software development activities, recent studies show the concern of introducing vulnerabilities into software codebase by AI programming assistants (e.g., Copilot, CodeWhisperer). In this work, we present Codexity, a security-focused code generation framework integrated with five LLMs. Codexity leverages the feedback of static analysis tools such as Infer and CppCheck to mitigate security vulnerabilities in LLM-generated programs. Our evaluation in a real-world benchmark with 751 automatically generated vulnerable subjects demonstrates Codexity can prevent 60% of the vulnerabilities being exposed to the software developer.
@article{kim2024codexity, title = {Codexity: Secure AI-assisted Code Generation}, author = {Kim, Sung Yong and Fan, Zhiyu and Noller, Yannic and Roychoudhury, Abhik}, journal = {arXiv preprint arXiv:2405.03927}, year = {2024}, doi = {https://doi.org/10.48550/arXiv.2405.03927}, } - APR@ICSE’24Program Repair Competition 2024Ridwan Shariffdeen, Yannic Noller, Martin Mirchev, Haifeng Ruan, Xiang Gao, Andreea Costea, Gregory J. Duck, and Abhik RoychoudhuryIn 2024 IEEE/ACM International Workshop on Automated Program Repair (APR), Nov 2024
This report outlines the objectives, methodology, challenges, and results of the first Automated Program Repair Competition held at the APR Workshop 2024. The competition utilized Cerberus, a program repair framework, to evaluate the program repair tools using different repair configurations for each track in the competition. The competition was organized in three phases: first the participants integrated their tools with Cerberus, second the integrated tools were tested using public benchmarks and participants were able to fix any identified issues. In the last phase, the submitted tools and baseline comparison tools were evaluated against private benchmark programs.
@inproceedings{aprcomp2024, title = {Program Repair Competition 2024}, author = {Shariffdeen, Ridwan and Noller, Yannic and Mirchev, Martin and Ruan, Haifeng and Gao, Xiang and Costea, Andreea and Duck, Gregory J. and Roychoudhury, Abhik}, booktitle = {2024 IEEE/ACM International Workshop on Automated Program Repair (APR)}, year = {2024}, doi = {https://doi.org/10.1145/3643788.3648015}, } - KLEE@ICSE’24Poster: Exploring Complexity Estimation with Symbolic Execution and Large Language ModelsAdrians Skapars, Youcheng Sun, Yannic Noller, and Corina S. PăsăreanuIn 4th International KLEE Workshop on Symbolic Execution, Apr 2024
Symbolic program analysis is a powerful technique that explores the program space and searches for bugs and security vulnerabilities. However, it suffers from path explosion and complex constraint solving, which limits its applicability in practice. On the other hand, large Language Models (LLMs) have shown great potential in program comprehension and code generation while suffering from the ability to provide correctness guarantees. This work explores the symbiosis of symbolic analysis and large language models. In particular, we focus on estimating worst-case complexities by expanding the reach of symbolic analysis using LLMs. We propose to compute the worst-case execution behavior for small inputs via symbolic analysis and leverage the power of LLMs to generalize the obtained constraints. Therefore, we build a closer integration of Symbolic PathFinder (SPF) and ChatGPT. Preliminary results indicate that LLMs like ChatGPT can help SPF detect patterns for the worst-case complexity analysis, amplifying its search for inputs that can trigger denial-of-service attacks. The results and insights gained in this work will help researchers and software practitioners to design and develop secure software systems in the future. All datasets and implemented tools will be made open-source following open-source principles.
- ICST’24Evolutionary Testing for Program RepairHaifeng Ruan, Hoang Lam Nguyen, Ridwan Shariffdeen, Yannic Noller, and Abhik RoychoudhuryIn 2024 17th IEEE International Conference on Software Testing, Verification and Validation (ICST), 2024
Automated program repair (APR) allows for autonomous software protection and improvement. Many proposed repair techniques rely on available test suites, since tests are available in real-world settings. Tests are incomplete specifications, however. As a result, repairs generated based on tests may suffer from the test overfitting problem. The patches produced by APR techniques may pass the given tests and thus be plausible, and yet be an incorrect patch. This hints towards more extensive test suites to guide program repair. Generating additional tests to improve the test suite quality is generally difficult because the oracle or expected observable behavior of the generated tests is unknown. In our work, we first construct additional oracles by instrumenting buggy programs from the Defects4J benchmark with the knowledge obtained from the available bug reports. Then, we formulate a coevolution approach that generates tests and repairs in a unified workflow. The complete workflow is implemented as an extension of the well-known Java testing framework EvoSuite. This includes re-purposing the search in EvoSuite to search for repairs (instead of searching for tests) and enables an easy adoption for developers who are already familiar with EvoSuite for test suite generation. The evaluation of our tool EvoRepair shows that coevolution has a positive impact on the quality of patches and tests. In future, we hope that coevolution of patches and tests can inspire new repair tools and techniques.
@inproceedings{evorepair, author = {Ruan, Haifeng and Nguyen, Hoang Lam and Shariffdeen, Ridwan and Noller, Yannic and Roychoudhury, Abhik}, booktitle = {2024 17th IEEE International Conference on Software Testing, Verification and Validation (ICST)}, title = {Evolutionary Testing for Program Repair}, year = {2024}, volume = {}, number = {}, pages = {105-116}, keywords = {Software testing;Java;Software protection;Instruments;Computer bugs;Maintenance engineering;Software;evolutionary testing;coevolution;automated program repair}, doi = {10.1109/ICST60714.2024.00058}, issn = {}, month = {}, } - IEEE Software’24Fuzzing, Symbolic Execution, and Expert Guidance for Better TestingIsmet Burak Kadron, Yannic Noller, Rohan Padhye, Tevfik Bultan, Corina S. Păsăreanu, and Koushik SenIEEE Software, 2024
Hybrid program analysis approaches, that combine static and dynamic analysis, have resulted in powerful tools for automated software testing. However, they are still limited in practice, where the identification and removal of software errors remains a costly manual process. In this paper we argue for hybrid techniques that allow minimal but critical intervention from experts, to better guide software testing. We review several of our works that realize this vision.
@article{ieee2024_hugs, author = {Kadron, Ismet Burak and Noller, Yannic and Padhye, Rohan and Bultan, Tevfik and Păsăreanu, Corina S. and Sen, Koushik}, journal = {IEEE Software}, title = {Fuzzing, Symbolic Execution, and Expert Guidance for Better Testing}, year = {2024}, volume = {41}, number = {1}, pages = {98-104}, keywords = {Fuzzing;Software;Generators;Estimation;Memory management;Benchmark testing;Expert systems;Test facilities}, doi = {10.1109/MS.2023.3237981}, issn = {1937-4194}, month = {}, }
2023
- ACM FAC’23JMLKelinci+: Detecting Semantic Bugs and Covering Branches with Valid Inputs Using Coverage-Guided Fuzzing and Runtime Assertion CheckingAmirfarhad Nilizadeh, Gary T. Leavens, Corina S. Păsăreanu, and Yannic NollerForm. Asp. Comput., Aug 2023
Testing to detect semantic bugs is essential, especially for critical systems. Coverage-guided fuzzing (CGF) and runtime assertion checking (RAC) are two well-known approaches for detecting semantic bugs. CGF aims to generate test inputs with high code coverage. However, while CGF tools can be equipped with sanitizers to detect a fixed set of semantic bugs, they can otherwise only detect bugs that lead to a crash. Thus, the first problem we address is how to help fuzzers detect previously unknown semantic bugs that do not lead to a crash. Moreover, a CGF tool may not necessarily cover all branches with valid inputs, although invalid inputs are useless for detecting semantic bugs. So, the second problem is how to guide a fuzzer to maximize coverage using only valid inputs. On the other hand, RAC monitors the expected behavior of a program dynamically and can only detect a semantic bug when a valid test input shows that the program does not satisfy its specification. Thus, the third problem is how to provide high-quality test inputs for a RAC that can trigger potential bugs. The combination of a CGF tool and RAC solves these problems and can cover branches with valid inputs and detect semantic bugs effectively. Our study uses RAC to guarantee that only valid inputs reach the program under test using the program’s specified preconditions and it also uses RAC to detect semantic bugs using specified postconditions. A prototype tool was developed for this study, named JMLKelinci+. Our results show that combining a CGF tool with RAC will lead to executing the program under test only with valid inputs and that this technique can effectively detect semantic bugs. Also, this idea improves the feedback given to a CGF tool, enabling it to cover all branches faster in programs with non-trivial preconditions.
@article{jmlkelinci, author = {Nilizadeh, Amirfarhad and Leavens, Gary T. and P\u{a}s\u{a}reanu, Corina S. and Noller, Yannic}, title = {JMLKelinci+: Detecting Semantic Bugs and Covering Branches with Valid Inputs Using Coverage-Guided Fuzzing and Runtime Assertion Checking}, year = {2023}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, issn = {0934-5043}, url = {https://doi.org/10.1145/3607538}, doi = {10.1145/3607538}, journal = {Form. Asp. Comput.}, month = aug, keywords = {Branch Coverage, Valid Inputs, Runtime Assertion Checking, Formal Verification, Semantic Bug, Testing, Guided Fuzzer}, } - ICSE-DEMO’23Cerberus: a Program Repair FrameworkRidwan Shariffdeen, Martin Mirchev, Yannic Noller, and Abhik RoychoudhuryIn 2023 IEEE/ACM 45th International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), May 2023
Automated Program Repair (APR) represents a suite of emerging technologies which attempt to automatically fix bugs and vulnerabilities in programs. APR is a rapidly growing field with new tools and benchmarks being added frequently. Yet a language agnostic repair framework is not available. We introduce Cerberus,a program repair framework integrated with 20 program repair tools and 9 repair benchmarks, coexisting in the same framework. Cerberusis capable of executing diverse set of program repair tasks, using multitude of program repair tools and benchmarks. Video: https://www.youtube.com/watchvbYtShpsGL68
@inproceedings{cerberus, author = {Shariffdeen, Ridwan and Mirchev, Martin and Noller, Yannic and Roychoudhury, Abhik}, booktitle = {2023 IEEE/ACM 45th International Conference on Software Engineering: Companion Proceedings (ICSE-Companion)}, title = {Cerberus: a Program Repair Framework}, year = {2023}, volume = {}, number = {}, pages = {73-77}, keywords = {}, doi = {10.1109/ICSE-Companion58688.2023.00028}, issn = {2574-1934}, month = may, }
2022
- arXiv’23Program repairXiang Gao, Yannic Noller, and Abhik RoychoudhuryarXiv preprint arXiv:2211.12787, May 2022
Automated program repair is an emerging technology which consists of a suite of techniques to automatically fix bugs or vulnerabilities in programs. In this paper, we present a comprehensive survey of the state of the art in program repair. We first study the different suite of techniques used including search based repair, constraint based repair and learning based repair. We then discuss one of the main challenges in program repair namely patch overfitting, by distilling a class of techniques which can alleviate patch overfitting. We then discuss classes of program repair tools, applications of program repair as well as uses of program repair in industry. We conclude the survey with a forward looking outlook on future usages of program repair, as well as research opportunities arising from work on code from large language models.
@article{gao2022program, title = {Program repair}, author = {Gao, Xiang and Noller, Yannic and Roychoudhury, Abhik}, journal = {arXiv preprint arXiv:2211.12787}, year = {2022}, doi = {https://doi.org/10.48550/arXiv.2211.12787}, } - IST’22VUDENC: Vulnerability Detection with Deep Learning on a Natural Codebase for PythonLaura Wartschinski, Yannic Noller, Thomas Vogel, Timo Kehrer, and Lars GrunskeInformation and Software Technology, May 2022
Context: Identifying potential vulnerable code is important to improve the security of our software systems. However, the manual detection of software vulnerabilities requires expert knowledge and is time-consuming, and must be supported by automated techniques. Objective: Such automated vulnerability detection techniques should achieve a high accuracy, point developers directly to the vulnerable code fragments, scale to real-world software, generalize across the boundaries of a specific software project, and require no or only moderate setup or configuration effort. Method: In this article, we present Vudenc (Vulnerability Detection with Deep Learning on a Natural Codebase), a deep learning-based vulnerability detection tool that automatically learns features of vulnerable code from a large and real-world Python codebase. Vudenc applies a word2vec model to identify semantically similar code tokens and to provide a vector representation. A network of long-short-term memory cells (LSTM) is then used to classify vulnerable code token sequences at a fine-grained level, highlight the specific areas in the source code that are likely to contain vulnerabilities, and provide confidence levels for its predictions. Results: To evaluate Vudenc, we used 1,009 vulnerability-fixing commits from different GitHub repositories that contain seven different types of vulnerabilities (SQL injection, XSS, Command injection, XSRF, Remote code execution, Path disclosure, Open redirect) for training. In the experimental evaluation, Vudenc achieves a recall of 78%–87%, a precision of 82%–96%, and an F1 score of 80%–90%. Vudenc’s code, the datasets for the vulnerabilities, and the Python corpus for the word2vec model are available for reproduction. Conclusions: Our experimental results suggest that Vudenc is capable of outperforming most of its competitors in terms of vulnerably detection capabilities on real-world software. Comparable accuracy was only achieved on synthetic benchmarks, within single projects, or on a much coarser level of granularity such as entire source code files.
@article{WARTSCHINSKI2022106809, title = {VUDENC: Vulnerability Detection with Deep Learning on a Natural Codebase for Python}, journal = {Information and Software Technology}, volume = {144}, pages = {106809}, year = {2022}, issn = {0950-5849}, doi = {https://doi.org/10.1016/j.infsof.2021.106809}, url = {https://www.sciencedirect.com/science/article/pii/S0950584921002421}, author = {Wartschinski, Laura and Noller, Yannic and Vogel, Thomas and Kehrer, Timo and Grunske, Lars}, keywords = {Static analysis, Vulnerability detection, Deep learning, Long-short-term memory network, Natural codebase, Software repository mining}, } - ICSE’22Trust Enhancement Issues in Program RepairYannic Noller, Ridwan Shariffdeen, Xiang Gao, and Abhik RoychoudhuryIn Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, Pennsylvania, May 2022
Automated program repair is an emerging technology that seeks to automatically rectify bugs and vulnerabilities using learning, search, and semantic analysis. Trust in automatically generated patches is necessary for achieving greater adoption of program repair. Towards this goal, we survey more than 100 software practitioners to understand the artifacts and setups needed to enhance trust in automatically generated patches. Based on the feedback from the survey on developer preferences, we quantitatively evaluate existing test-suite based program repair tools. We find that they cannot produce high-quality patches within a top-10 ranking and an acceptable time period of 1 hour. The developer feedback from our qualitative study and the observations from our quantitative examination of existing repair tools point to actionable insights to drive program repair research. Specifically, we note that producing repairs within an acceptable time-bound is very much dependent on leveraging an abstract search space representation of a rich enough search space. Moreover, while additional developer inputs are valuable for generating or ranking patches, developers do not seem to be interested in a significant human-in-the-loop interaction.
@inproceedings{trustapr_icse2022, author = {Noller, Yannic and Shariffdeen, Ridwan and Gao, Xiang and Roychoudhury, Abhik}, title = {Trust Enhancement Issues in Program Repair}, year = {2022}, isbn = {9781450392211}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3510003.3510040}, doi = {10.1145/3510003.3510040}, booktitle = {Proceedings of the 44th International Conference on Software Engineering}, pages = {2228–2240}, numpages = {13}, location = {Pittsburgh, Pennsylvania}, series = {ICSE '22}, }
2021
- ISSTA’21QFuzz: Quantitative Fuzzing for Side ChannelsYannic Noller and Saeid Tizpaz-NiariIn Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual, Denmark, May 2021
Side channels pose a significant threat to the confidentiality of software systems. Such vulnerabilities are challenging to detect and evaluate because they arise from non-functional properties of software such as execution times and require reasoning on multiple execution traces. Recently, noninterference notions have been adapted in static analysis, symbolic execution, and greybox fuzzing techniques. However, noninterference is a strict notion and may reject security even if the strength of information leaks are weak. A quantitative notion of security allows for the relaxation of noninterference and tolerates small (unavoidable) leaks. Despite progress in recent years, the existing quantitative approaches have scalability limitations in practice. In this work, we present QFuzz, a greybox fuzzing technique to quantitatively evaluate the strength of side channels with a focus on min entropy. Min entropy is a measure based on the number of distinguishable observations (partitions) to assess the resulting threat from an attacker who tries to compromise secrets in one try. We develop a novel greybox fuzzing equipped with two partitioning algorithms that try to maximize the number of distinguishable observations and the cost differences between them. We evaluate QFuzz on a large set of benchmarks from existing work and real-world libraries (with a total of 70 subjects). QFuzz compares favorably to three state-of-the-art detection techniques. QFuzz provides quantitative information about leaks beyond the capabilities of all three techniques. Crucially, we compare QFuzz to a state-of-the-art quantification tool and find that QFuzz significantly outperforms the tool in scalability while maintaining similar precision. Overall, we find that our approach scales well for real-world applications and provides useful information to evaluate resulting threats. Additionally, QFuzz identifies a zero-day side-channel vulnerability in a security critical Java library that has since been confirmed and fixed by the developers.
@inproceedings{qfuzz_issta2021, author = {Noller, Yannic and Tizpaz-Niari, Saeid}, title = {QFuzz: Quantitative Fuzzing for Side Channels}, year = {2021}, isbn = {9781450384599}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3460319.3464817}, doi = {10.1145/3460319.3464817}, booktitle = {Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis}, pages = {257–269}, numpages = {13}, keywords = {vulnerability detection, fuzzing, quantification, side-channel analysis, dynamic analysis}, location = {Virtual, Denmark}, series = {ISSTA 2021}, } - CAV’21NNrepair: Constraint-Based Repair of Neural Network ClassifiersMuhammad Usman, Divya Gopinath, Youcheng Sun, Yannic Noller, and Corina S. PăsăreanuIn Computer Aided Verification, May 2021
We present NNrepair, a constraint-based technique for repairing neural network classifiers. The technique aims to fix the logic of the network at an intermediate layer or at the last layer. NNrepair first uses fault localization to find potentially faulty network parameters (such as the weights) and then performs repair using constraint solving to apply small modifications to the parameters to remedy the defects. We present novel strategies to enable precise yet efficient repair such as inferring correctness specifications to act as oracles for intermediate layer repair, and generation of experts for each class. We demonstrate the technique in the context of three different scenarios: (1) Improving the overall accuracy of a model, (2) Fixing security vulnerabilities caused by poisoning of training data and (3) Improving the robustness of the network against adversarial attacks. Our evaluation on MNIST and CIFAR-10 models shows that NNrepair can improve the accuracy by 45.56% points on poisoned data and 10.40% points on adversarial data. NNrepair also provides small improvement in the overall accuracy of models, without requiring new data or re-training.
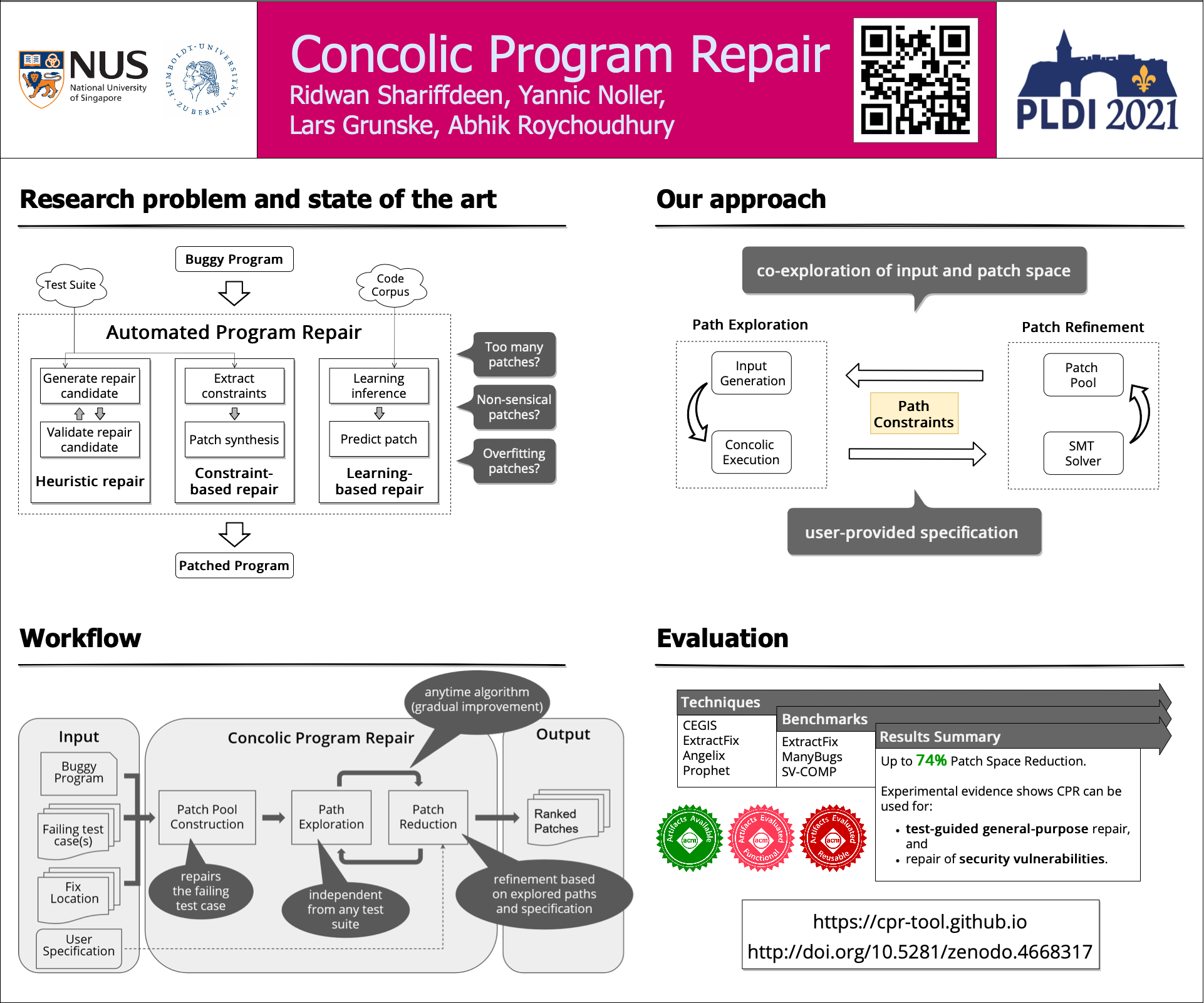
@inproceedings{nnrepair, author = {Usman, Muhammad and Gopinath, Divya and Sun, Youcheng and Noller, Yannic and P{\u{a}}s{\u{a}}reanu, Corina S.}, editor = {Silva, Alexandra and Leino, K. Rustan M.}, title = {NNrepair: Constraint-Based Repair of Neural Network Classifiers}, booktitle = {Computer Aided Verification}, year = {2021}, publisher = {Springer International Publishing}, address = {Cham}, pages = {3--25}, isbn = {978-3-030-81685-8}, } - PLDI’21Concolic Program RepairRidwan Shariffdeen, Yannic Noller, Lars Grunske, and Abhik RoychoudhuryIn Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, Virtual, Canada, May 2021
Automated program repair reduces the manual effort in fixing program errors. However, existing repair techniques modify a buggy program such that it passes given tests. Such repair techniques do not discriminate between correct patches and patches that overfit the available tests (breaking untested but desired functionality). We propose an integrated approach for detecting and discarding overfitting patches via systematic co-exploration of the patch space and input space. We leverage concolic path exploration to systematically traverse the input space (and generate inputs), while ruling out significant parts of the patch space. Given a long enough time budget, this approach allows a significant reduction in the pool of patch candidates, as shown by our experiments. We implemented our technique in the form of a tool called ’CPR’ and evaluated its efficacy in reducing the patch space by discarding overfitting patches from a pool of plausible patches. We evaluated our approach for fixing real-world software vulnerabilities and defects, for fixing functionality errors in programs drawn from SV-COMP benchmarks used in software verification, as well as for test-suite guided repair. In our experiments, we observed a patch space reduction due to our concolic exploration of up to 74% for fixing software vulnerabilities and up to 63% for SV-COMP programs. Our technique presents the viewpoint of gradual correctness - repair run over longer time leads to less overfitting fixes.
@inproceedings{cpr, author = {Shariffdeen, Ridwan and Noller, Yannic and Grunske, Lars and Roychoudhury, Abhik}, title = {Concolic Program Repair}, year = {2021}, isbn = {9781450383912}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3453483.3454051}, doi = {10.1145/3453483.3454051}, booktitle = {Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation}, pages = {390–405}, numpages = {16}, keywords = {patch overfitting, program repair, symbolic execution, program synthesis}, location = {Virtual, Canada}, series = {PLDI 2021}, } - ICSE-DEMO’21NEUROSPF: A Tool for the Symbolic Analysis of Neural NetworksMuhammad Usman, Yannic Noller, Corina S. Păsăreanu, Youcheng Sun, and Divya GopinathIn 2021 IEEE/ACM 43rd International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), May 2021
This paper presents NEUROSPF, a tool for the symbolic analysis of neural networks. Given a trained neural network model, the tool extracts the architecture and model parameters and translates them into a Java representation that is amenable for analysis using the Symbolic PathFinder symbolic execution tool. Notably, NEUROSPF encodes specialized peer classes for parsing the model’s parameters, thereby enabling efficient analysis. With NEUROSPF the user has the flexibility to specify either the inputs or the network internal parameters as symbolic, promoting the application of program analysis and testing approaches from software engineering to the field of machine learning. For instance, NEUROSPF can be used for coverage-based testing and test generation, finding adversarial examples and also constraint-based repair of neural networks, thus improving the reliability of neural networks and of the applications that use them. Video URL: https://youtu.be/seal8fG78LI.
@inproceedings{neurospf, author = {Usman, Muhammad and Noller, Yannic and Păsăreanu, Corina S. and Sun, Youcheng and Gopinath, Divya}, booktitle = {2021 IEEE/ACM 43rd International Conference on Software Engineering: Companion Proceedings (ICSE-Companion)}, title = {NEUROSPF: A Tool for the Symbolic Analysis of Neural Networks}, year = {2021}, volume = {}, number = {}, pages = {25-28}, keywords = {}, doi = {10.1109/ICSE-Companion52605.2021.00027}, issn = {2574-1926}, month = may, }
{kind=link}
2020
- SSBSE’20Evolutionary Grammar-Based FuzzingMartin Eberlein, Yannic Noller, Thomas Vogel, and Lars GrunskeIn Search-Based Software Engineering, May 2020
A fuzzer provides randomly generated inputs to a targeted software to expose erroneous behavior. To efficiently detect defects, generated inputs should conform to the structure of the input format and thus, grammars can be used to generate syntactically correct inputs. In this context, fuzzing can be guided by probabilities attached to competing rules in the grammar, leading to the idea of probabilistic grammar-based fuzzing. However, the optimal assignment of probabilities to individual grammar rules to effectively expose erroneous behavior for individual systems under test is an open research question. In this paper, we present EvoGFuzz, an evolutionary grammar-based fuzzing approach to optimize the probabilities to generate test inputs that may be more likely to trigger exceptional behavior. The evaluation shows the effectiveness of EvoGFuzz in detecting defects compared to probabilistic grammar-based fuzzing (baseline). Applied to ten real-world applications with common input formats (JSON, JavaScript, or CSS3), the evaluation shows that EvoGFuzz achieved a significantly larger median line coverage for all subjects by up to 48% compared to the baseline. Moreover, EvoGFuzz managed to expose 11 unique defects, from which five have not been detected by the baseline.
@inproceedings{evogfuzz, author = {Eberlein, Martin and Noller, Yannic and Vogel, Thomas and Grunske, Lars}, editor = {Aleti, Aldeida and Panichella, Annibale}, title = {Evolutionary Grammar-Based Fuzzing}, booktitle = {Search-Based Software Engineering}, year = {2020}, publisher = {Springer International Publishing}, address = {Cham}, pages = {105--120}, isbn = {978-3-030-59762-7}, } - ICSE’20HyDiff: Hybrid Differential Software AnalysisYannic Noller, Corina S. Păsăreanu, Marcel Böhme, Youcheng Sun, Hoang Lam Nguyen, and Lars GrunskeIn Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, Seoul, South Korea, May 2020
Detecting regression bugs in software evolution, analyzing side-channels in programs and evaluating robustness in deep neural networks (DNNs) can all be seen as instances of differential software analysis, where the goal is to generate diverging executions of program paths. Two executions are said to be diverging if the observable program behavior differs, e.g., in terms of program output, execution time, or (DNN) classification. The key challenge of differential software analysis is to simultaneously reason about multiple program paths, often across program variants.This paper presents HyDiff, the first hybrid approach for differential software analysis. HyDiff integrates and extends two very successful testing techniques: Feedback-directed greybox fuzzing for efficient program testing and shadow symbolic execution for systematic program exploration. HyDiff extends greybox fuzzing with divergence-driven feedback based on novel cost metrics that also take into account the control flow graph of the program. Furthermore HyDiff extends shadow symbolic execution by applying four-way forking in a systematic exploration and still having the ability to incorporate concrete inputs in the analysis. HyDiff applies divergence revealing heuristics based on resource consumption and control-flow information to efficiently guide the symbolic exploration, which allows its efficient usage beyond regression testing applications. We introduce differential metrics such as output, decision and cost difference, as well as patch distance, to assist the fuzzing and symbolic execution components in maximizing the execution divergence.We implemented our approach on top of the fuzzer AFL and the symbolic execution framework Symbolic PathFinder. Weillustrate HyDiff on regression and side-channel analysis for Java bytecode programs, and further show how to use HyDiff for robustness analysis of neural networks.
@inproceedings{hydiff, author = {Noller, Yannic and P\u{a}s\u{a}reanu, Corina S. and B\"{o}hme, Marcel and Sun, Youcheng and Nguyen, Hoang Lam and Grunske, Lars}, title = {HyDiff: Hybrid Differential Software Analysis}, year = {2020}, isbn = {9781450371216}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3377811.3380363}, doi = {10.1145/3377811.3380363}, booktitle = {Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering}, pages = {1273–1285}, numpages = {13}, keywords = {differential program analysis, symbolic execution, fuzzing}, location = {Seoul, South Korea}, series = {ICSE '20}, }
2019
- JPF’19Complete Shadow Symbolic Execution with Java PathFinderYannic Noller, Hoang Lam Nguyen, Minxing Tang, Timo Kehrer, and Lars GrunskeSIGSOFT Softw. Eng. Notes, Dec 2019Java PathFinder Workshop 2019
Regression testing ensures the correctness of the software during its evolution, with special attention on the absence of unintended side-e ects that might be introduced by changes. However, the manual creation of regression test cases, which expose divergent behavior, needs a lot of e ort. A solution is the idea of shadow symbolic execution, which takes a uni ed version of the old and the new programs and performs symbolic execution guided by concrete values to explore the changed behavior.In this work, we adapt the idea of shadow symbolic execution (SSE) and combine complete/standard symbolic execution with the idea of four-way forking to expose diverging behavior. There- fore, our approach attempts to comprehensively test the new be- haviors introduced by a change. We implemented our approach in the tool ShadowJPF+, which performs complete shadow sym- bolic execution on Java bytecode. It is an extension of the tool ShadowJPF, which is based on Symbolic PathFinder. We applied our tool on 79 examples, for which it was able to reveal more di- verging behaviors than common shadow symbolic execution. Ad- ditionally, the approach has been applied on a real-world patch for the Joda-Time library, for which it successfully generated test cases that expose a regression error.
@article{jpf_shadow_plus, author = {Noller, Yannic and Nguyen, Hoang Lam and Tang, Minxing and Kehrer, Timo and Grunske, Lars}, title = {Complete Shadow Symbolic Execution with Java PathFinder}, year = {2019}, issue_date = {October 2019}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, volume = {44}, number = {4}, issn = {0163-5948}, url = {https://doi.org/10.1145/3364452.33644558}, doi = {10.1145/3364452.33644558}, journal = {SIGSOFT Softw. Eng. Notes}, month = dec, pages = {15–16}, numpages = {2}, note = {Java PathFinder Workshop 2019}, keywords = {symbolic execution, regression testing, symbolic pathfinder}, } - TACAS’19Symbolic Pathfinder for SV-COMPYannic Noller, Corina S. Păsăreanu, Aymeric Fromherz, Xuan-Bach D. Le, and Willem VisserIn Tools and Algorithms for the Construction and Analysis of Systems, Dec 2019
This paper describes the benchmark entry for Symbolic Pathfinder, a symbolic execution tool for Java bytecode. We give a brief description of the tool and we describe the particular run configuration that was used in the SV-COMP competition. Furthermore, we comment on the competition results and we outline some directions for future work.
@inproceedings{spf_svcomp, author = {Noller, Yannic and P{\u{a}}s{\u{a}}reanu, Corina S. and Fromherz, Aymeric and Le, Xuan-Bach D. and Visser, Willem}, editor = {Beyer, Dirk and Huisman, Marieke and Kordon, Fabrice and Steffen, Bernhard}, title = {Symbolic Pathfinder for SV-COMP}, booktitle = {Tools and Algorithms for the Construction and Analysis of Systems}, year = {2019}, publisher = {Springer International Publishing}, address = {Cham}, pages = {239--243}, isbn = {978-3-030-17502-3}, } - ICSE’19DifFuzz: Differential Fuzzing for Side-channel AnalysisShirin Nilizadeh, Yannic Noller, and Corina S. PăsăreanuIn Proceedings of the 41st International Conference on Software Engineering, Montreal, Quebec, Canada, Dec 2019
Side-channel attacks allow an adversary to uncover secret program data by observing the behavior of a program with respect to a resource, such as execution time, consumed memory or response size. Side-channel vulnerabilities are difficult to reason about as they involve analyzing the correlations between resource usage over multiple program paths. We present DifFuzz, a fuzzing-based approach for detecting side-channel vulnerabilities related to time and space. DifFuzz automatically detects these vulnerabilities by analyzing two versions of the program and using resource-guided heuristics to find inputs that maximize the difference in resource consumption between secret-dependent paths. The methodology of DifFuzz is general and can be applied to programs written in any language. For this paper, we present an implementation that targets analysis of Java programs, and uses and extends the Kelinci and AFL fuzzers. We evaluate DifFuzz on a large number of Java programs and demonstrate that it can reveal unknown side-channel vulnerabilities in popular applications. We also show that DifFuzz compares favorably against Blazer and Themis, two state-of-the-art analysis tools for finding side-channels in Java programs.
@inproceedings{diffuz, author = {Nilizadeh, Shirin and Noller, Yannic and P\u{a}s\u{a}reanu, Corina S.}, title = {DifFuzz: Differential Fuzzing for Side-channel Analysis}, booktitle = {Proceedings of the 41st International Conference on Software Engineering}, series = {ICSE '19}, year = {2019}, location = {Montreal, Quebec, Canada}, pages = {176--187}, numpages = {12}, url = {https://doi.org/10.1109/ICSE.2019.00034}, doi = {10.1109/ICSE.2019.00034}, acmid = {3339529}, publisher = {IEEE Press}, address = {Piscataway, NJ, USA}, keywords = {dynamic analysis, fuzzing, side-channel analysis, vulnerability detection}, }
2018
- ASE-DocSym’18Differential Program Analysis with Fuzzing and Symbolic ExecutionYannic NollerIn Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, Dec 2018
Differential program analysis means to identify the behavioral divergences in one or multiple programs, and it can be classified into two categories: identify the behavioral divergences (1) between two program versions for the same input (aka regression analysis), and (2) for the same program with two different inputs (e.g, side-channel analysis). Most of the existent approaches for both subproblems try to solve it with single techniques, which suffer from its weaknesses like scalability issues or imprecision. This research proposes to combine two very strong techniques, namely fuzzing and symbolic execution to tackle these problems and provide scalable solutions for real-world applications. The proposed approaches will be implemented on top of state-of-the-art tools like AFL and Symbolic PathFinder to evaluate them against existent work.
@inproceedings{ase2018, author = {Noller, Yannic}, title = {Differential Program Analysis with Fuzzing and Symbolic Execution}, year = {2018}, isbn = {9781450359375}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3238147.3241537}, doi = {10.1145/3238147.3241537}, booktitle = {Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering}, pages = {944–947}, numpages = {4}, keywords = {Symbolic Execution, Fuzzing, Differential Program Analysis}, location = {Montpellier, France}, series = {ASE '18}, } - ISSTA’18Badger: Complexity Analysis with Fuzzing and Symbolic ExecutionYannic Noller, Rody Kersten, and Corina S. PăsăreanuIn Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, Amsterdam, Netherlands, Dec 2018
Hybrid testing approaches that involve fuzz testing and symbolic execution have shown promising results in achieving high code coverage, uncovering subtle errors and vulnerabilities in a variety of software applications. In this paper we describe Badger - a new hybrid approach for complexity analysis, with the goal of discovering vulnerabilities which occur when the worst-case time or space complexity of an application is significantly higher than the average case. Badger uses fuzz testing to generate a diverse set of inputs that aim to increase not only coverage but also a resource-related cost associated with each path. Since fuzzing may fail to execute deep program paths due to its limited knowledge about the conditions that influence these paths, we complement the analysis with a symbolic execution, which is also customized to search for paths that increase the resource-related cost. Symbolic execution is particularly good at generating inputs that satisfy various program conditions but by itself suffers from path explosion. Therefore, Badger uses fuzzing and symbolic execution in tandem, to leverage their benefits and overcome their weaknesses. We implemented our approach for the analysis of Java programs, based on Kelinci and Symbolic PathFinder. We evaluated Badger on Java applications, showing that our approach is significantly faster in generating worst-case executions compared to fuzzing or symbolic execution on their own.
@inproceedings{badger, author = {Noller, Yannic and Kersten, Rody and P\u{a}s\u{a}reanu, Corina S.}, title = {Badger: Complexity Analysis with Fuzzing and Symbolic Execution}, year = {2018}, isbn = {9781450356992}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3213846.3213868}, doi = {10.1145/3213846.3213868}, booktitle = {Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis}, pages = {322–332}, numpages = {11}, keywords = {Denial-of-Service, Complexity Analysis, Symbolic Execution, Fuzzing}, location = {Amsterdam, Netherlands}, series = {ISSTA 2018}, } - JSS’18Supporting semi-automatic co-evolution of architecture and fault tree modelsSinem Getir, Lars Grunske, André Hoorn, Timo Kehrer, Yannic Noller, and Matthias TichyJournal of Systems and Software, Dec 2018
During the whole life-cycle of software-intensive systems in safety-critical domains, system models must consistently co-evolve with quality evaluation models like fault trees. However, performing these co-evolution steps is a cumbersome and often manual task. To understand this problem in detail, we have analyzed the evolution and mined common changes of architecture and fault tree models for a set of evolution scenarios of a part of a factory automation system called Pick and Place Unit. On the other hand, we designed a set of intra- and inter-model transformation rules which fully cover the evolution scenarios of the case study and which offer the potential to semi-automate the co-evolution process. In particular, we validated these rules with respect to completeness and evaluated them by a comparison to typical visual editor operations. Our results show a significant reduction of the amount of required user interactions in order to realize the co-evolution.
@article{jss2018, title = {Supporting semi-automatic co-evolution of architecture and fault tree models}, journal = {Journal of Systems and Software}, volume = {142}, pages = {115-135}, year = {2018}, issn = {0164-1212}, doi = {https://doi.org/10.1016/j.jss.2018.04.001}, url = {https://www.sciencedirect.com/science/article/pii/S0164121218300657}, author = {Getir, Sinem and Grunske, Lars and van Hoorn, André and Kehrer, Timo and Noller, Yannic and Tichy, Matthias}, keywords = {System architecture, Fault trees, Safety, Model co-evolution, Model transformation}, } - ICSE’18Semantic Program Repair Using a Reference ImplementationSergey Mechtaev, Manh-Dung Nguyen, Yannic Noller, Lars Grunske, and Abhik RoychoudhuryIn Proceedings of the 40th International Conference on Software Engineering, Gothenburg, Sweden, Dec 2018
Automated program repair has been studied via the use of techniques involving search, semantic analysis and artificial intelligence. Most of these techniques rely on tests as the correctness criteria, which causes the test overfitting problem. Although various approaches such as learning from code corpus have been proposed to address this problem, they are unable to guarantee that the generated patches generalize beyond the given tests. This work studies automated repair of errors using a reference implementation. The reference implementation is symbolically analyzed to automatically infer a specification of the intended behavior. This specification is then used to synthesize a patch that enforces conditional equivalence of the patched and the reference programs. The use of the reference implementation as an implicit correctness criterion alleviates overfitting in test-based repair. Besides, since we generate patches by semantic analysis, the reference program may have a substantially different implementation from the patched program, which distinguishes our approach from existing techniques for regression repair like Relifix. Our experiments in repairing the embedded Linux Busybox with GNU Coreutils as reference (and vice-versa) revealed that the proposed approach scales to real-world programs and enables the generation of more correct patches.
@inproceedings{semgraft, author = {Mechtaev, Sergey and Nguyen, Manh-Dung and Noller, Yannic and Grunske, Lars and Roychoudhury, Abhik}, title = {Semantic Program Repair Using a Reference Implementation}, year = {2018}, isbn = {9781450356381}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3180155.3180247}, doi = {10.1145/3180155.3180247}, booktitle = {Proceedings of the 40th International Conference on Software Engineering}, pages = {129–139}, numpages = {11}, keywords = {program repair, verification, debugging}, location = {Gothenburg, Sweden}, series = {ICSE '18}, } - JPF’17Shadow Symbolic Execution with Java PathFinderYannic Noller, Hoang Lam Nguyen, Minxing Tang, and Timo KehrerSIGSOFT Softw. Eng. Notes, Jan 2018Java PathFinder Workshop 2017
Regression testing ensures that a software system when it evolves still performs correctly and that the changes introduce no unintended side-effects. However, the creation of regression test cases that show divergent behavior needs a lot of effort. A solutionis the idea of shadow symbolic execution, originally implemented based on KLEE for programs written in C, which takes a unified version of the old and the new program and performs symbolic execution guided by concrete values to explore the changed behavior. In this work, we apply the idea of shadow symbolic execution to Java programs and, hence, provide an extension of the Java PathFinder (JPF) project to perform shadow symbolic execution on Java bytecode. The extension has been applied on several subjects from the JPF test classes where it successfully generated test inputs that expose divergences relevant for regression testing.
@article{jpf_shadow, author = {Noller, Yannic and Nguyen, Hoang Lam and Tang, Minxing and Kehrer, Timo}, title = {Shadow Symbolic Execution with Java PathFinder}, year = {2018}, issue_date = {October 2017}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, volume = {42}, number = {4}, issn = {0163-5948}, url = {https://doi.org/10.1145/3149485.3149492}, doi = {10.1145/3149485.3149492}, journal = {SIGSOFT Softw. Eng. Notes}, month = jan, pages = {1–5}, numpages = {5}, keywords = {Java PathFinder, Symbolic Execution, Regression Testcase Generation, Symbolic PathFinder, Software Engineering}, note = {Java PathFinder Workshop 2017}, }
Note: Above are the author’s versions of the works. They are posted here for your personal use. Not for redistribution. The definitive versions were published in the referenced conferences / journals.